现实生活中预测的根本难题在于无处不在的复杂性,比如股市,自然灾害, 长久的天气预测,都很难做到精准。 这与迄今人类做的最成功的预测-经典物理学的预测大相径庭,物理预测的核心方法是动力学方法, 即人们由实验出发抽象出引起运动改变的原因, 把这些原因量化为变量,用微分方程来描述, 从而取得对整个未来的精确解。
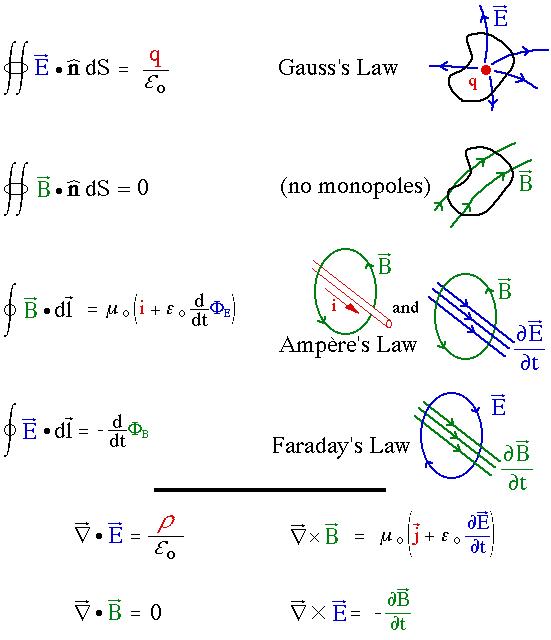
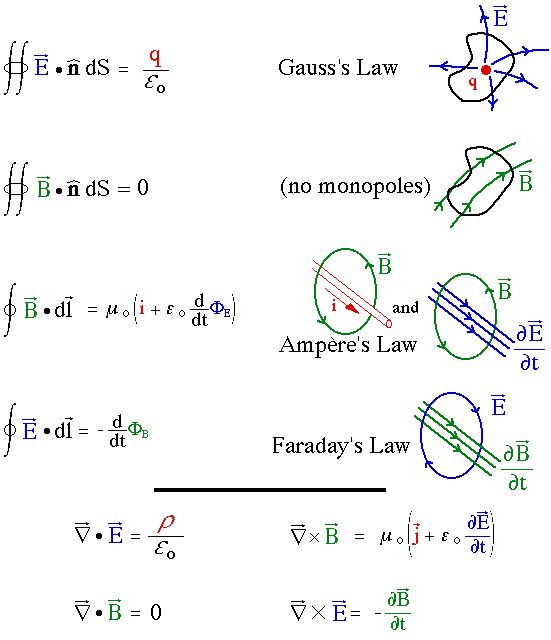
图: 麦克斯韦方程组: 一组精准的有关电场和磁场的微积分方程, 可以预测从光波的速度到磁线圈转动发电任何的电磁学现象。
但是这种思维模式在人类试图理解那些和自身生存最相关的东西时候却节节溃败。


图: 你能举出几种预测很重要但是人类怎么做都很难预测的领域吗?
这种溃败首先是, 还原论(把整体拆成部分)思维的溃败。量子物理里,我们可以通过了解金属原子电子云的性质, 很好的预测金属的属性。 而你却无法通过了解市场上每个人的特性就很好的预测整个市场走势。在市场这种系统里, 有两个关键要素, 一个是个体和个体之间的互相作用(博弈),一个是系统与外部环境(地球资源)之间的相互作用(反馈),因此而形成复杂模式(Pattern), 这种模式通常无法预测。 这种类型的系统我们通常定义为复杂系统: 由大量单元互相作用组成的系统, 由于集体行为的非线性(总体不等于个体之和), 而形成具备无数层级的复杂组织。或者称为涌现性。 复杂科学即研究复杂系统的一套联系不同尺度现象的数学方法。
复杂系统难以预测的原理可以从以下几方面理解:
1, 高维诅咒: 构成现实生活的系统往往被大量未知变量决定, 比如生物由无数的细胞组成。 基因,是由无数独立的单元组成的, 市场, 由无数的交易者组成, 这些用物理的描述方法来预测, 就是极高维度空间的运动问题。维度,首先使得再简单的方程形式都十分复杂难解。
2, 非线性诅咒:高维度系统的维度之间具有复杂的相互作用,导致我们不能把系统分解为单一维度然后做加法的方法研究。 高维加上非线性我们将得到对初级极为敏感的混沌系统。
3, 反馈诅咒: 复杂系统中反馈无处不在, 即使是一个简单的一维系统, 反馈也可以使得系统的特性很丰富, 最典型的反馈是某种记忆效应, 使得系统产生复杂的路径依赖, 此刻你的现实与历史深刻关联,而关联方法导致复杂的模式产生。
反身性是一种由预测产生的特殊反馈, 当你预测股市的价格, 会引起你的交易策略变化从而影响你的预测, 是为反身性。
4, 随机诅咒: 复杂系统往往含有不包含确定规律的随机噪声,加上这些噪声, 系统的行为更加难预测, 而很多时候, 我们也无法区分一个系统里发现的模式是噪声导致还是由于元件之间的相互作用。
这四大诅咒是这些系统难以理解和预测的原因, 而这个时候, 复杂系统和机器学习的方法论可以作为一种非常有力的手段帮我们从复杂性中挖掘模式。
第一种方法叫Model approch(模型驱动), 即想办法找到事物变化的原因, 用一种降维的思路列出微分方程, 即从非常繁复的要素中化简出最重要的一个或者两个, 从而化繁琐为简单,不管三七二十一先抓住主要矛盾。其中的范例便是非线性动力学。
1, 如果一个系统可以化简到一维, 那么你只需要研究其内部存在的反馈性质并描述它即可。 负反馈导致稳定定点产生, 正反馈导致不稳定性。 很多事物多可以抽象为一维系统,包括简单环境下的人口增长问题。
2, 如果一个系统可以化简到二维, 那么你需要研究两个维度间的相互作用,最终可以互为负反馈而稳定下来,互为正反馈而爆发,或者产生此消彼长的周期轨道。 比如恋爱中的男女是个二维系统, 互为负反馈就回到普通朋友, 互为正反馈在爱欲中爆发-比如罗密欧与朱丽叶, 此消彼长那是玩捉迷藏的周期游戏。
3, 如果一个系统是三维的, 则混沌可能产生。 混沌即对初值极为敏感的运动体系。 你一旦偏离既定轨道一点, 即几乎无法回去。
4, 如果一个系统大于三维, 那么你需要用一个复杂网络描述它的运动, 这个时候我们可以得到我们复杂系统的主角- collective phenomena & emergence。 复杂网络的性质主要取决于单体间相互作用的方式, 以及系统与外界交换能量的方法, 这两者又息息相关。 最终我们得到涌现。 复杂网络的动力学往往混沌难以预测,
对于高维混沌系统, 第一个方法也只能给出对事物定性的描述, 而我们可以寄出我们的第二种方法: 先不管数据背后错综复杂的动因,而是直接以数据驱动我们的预测。 这其中的哲学内涵即贝叶斯分析框架: 即先不预测, 而是列出所有可能的结果及根据以往知识和经验每种结果发生的可能性(先验概率),之后不停吸收新观测数据, 调整每种可能结果的概率大小(后验概率),将想得到的结果概率最大化(MAP)最终做出决策。
如果你把贝叶斯分析的框架自动化, 让电脑完成, 你就得到机器学习的最基本框架。
机器学习如果可以进入一个问题中, 往往要具备三个条件: 1, 系统中可能存在模式 2, 这种模式不是一般解析手段可以猜测到的。 3, 数据可以获取。 如果三点有一点不符,都很难运用机器学习。
机器学习的一个核心任务即模式识别, 也可以看出它和刚才讲的复杂系统提到的模式的关系。我们讲复杂系统难以通过其成分的分析对整体进行预测,然而由于复杂系统通常存在模式, 我们通常可以模式识别来对系统进行归类, 并预测各种可能的未来结果。比如一个投行女因为工作压力过大而自杀了, 那么在她之前的活动行为数据(比如点击手机的某些app的频率)里是否可能存在某种模式? 这种模式是否可以判定她之后的行为类型?并且这个过程可否通过历史数据由计算机学习?如果都可以,这就是一个机器学习问题。
刚才讲的几大诅咒, 高维, 非线性, 复杂反馈,随机性也称为机器学习需要核心面对的几大困难, 由此得到一系列机器学习的核心算法。
机器学习在现实生活中被用于非常多的方面, 最常见的如商务洞察(分类,聚类, 推荐算法), 智能语音语义服务(时间序列处理,循环网络), 各种自动鉴别系统如人脸识别,虹膜识别 ,癌症检测(深度卷积网络), 阿尔法狗,机器人控制(深度强化学习算法)。 而由方法论分, 又可以分成有监督学习, 无监督学习, 和强化学习。
我着重讲了几种机器学习的基本方法:
1. 贝叶斯决策的基本思想:
你要让机器做决策, 一个基本的思路是从统计之前数据挖掘已有的模式(pattern)入手, 来掌握新的数据中蕴含的信息。 这个pattern在有监督学习的例子里, 就是把某种数据结构和假设结论关联起来的过程,我们通常用条件概率描述。 那么让机器做决策, 就是通过不停的通过新数据来调整这个数据结构(特征)与假设结果对应的条件概率。通常我们要把我们预先对某领域的知识作为预设(prior),它是一个假设结果在数据收集前的概率密度函数,然后通过收集数据我们得到调整后的假设结果的概率密度函数, 被称为后验概率(posterior),最终的目标是机器得到的概率密度函数与真实情况最匹配, 即 Maximum a posterior(MAP), 这是机器学习的最终目标。
2, 朴素贝叶斯分类器到贝叶斯网络:
分类,是决策的基础,商业中要根据收集客户的消费特征将客户分类从而精准营销。 金融中你要根据一些交易行为的基本特征将交易者做分类。 从贝叶斯分析的基本思路出发我们可以迅速得到几种分类器。
首当其冲的朴素贝叶斯分类器,它是机器学习一个特别质朴而深刻的模型:当你要根据多个特征而非一个特征对数据进行分类的时候,我们可以假设这些特征相互独立(或者你先假设相互独立),然后利用条件概率乘法法则得到每一个分类的概率, 然后选择概率最大的那个作为机器的判定。
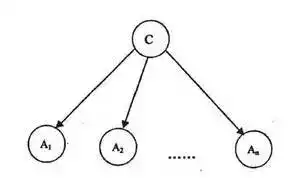
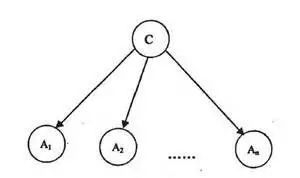
图: 朴素贝叶斯分类器的基本框架, c是类别, A是特征。
如果你要根据做出分类的特征不是互相独立,而是互相具有复杂关联,这也是大部分时候我们面临问题的真相, 我们需要更复杂的工具即贝叶斯网络。 比如你对某些病例的判定, 咳嗽, 发烧, 喉咙肿痛都可以看做扁条体发炎的症候, 而这些症候有些又互为因果, 此时贝叶斯网络是做出此类判定的最好方法。 构建一个贝叶斯网络的关键是建立图模型 , 我们需要把所有特征间的因果联系用箭头连在一起, 最后计算各个分类的概率。
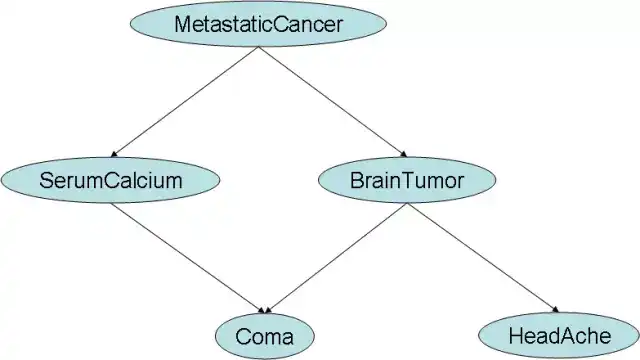

图:贝叶斯网络对MetaStatic Cancer的诊断,此处的特征具有复杂因果联系
贝叶斯分析结合一些更强的假设,可以让我们得到一些经常使用的通用分类器, 如逻辑斯提回归模型,这里我们用到了物理里的熵最大假设得到玻尔兹曼分布, 因此之前简单贝叶斯的各个特征成立概率的乘积就可以转化为指数特征的加权平均。 这是我们日常最常用的分类器之一。 更加神奇的是, 这个东西形式上同单层神经网络。
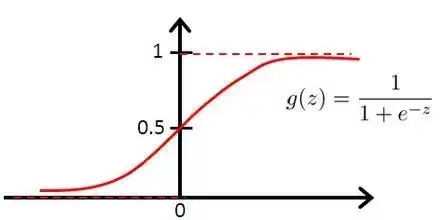

图: logistic函数,数学形式通玻尔兹曼分布, 物理里熵最大模型的体现
3, 贝叶斯时间序列分析之隐马模型:
贝叶斯时间序列分析被用于挖掘存储于时间中的模式,时间序列值得是一组随时间变化的随机变量,比如玩牌的时候你对手先后撒出的牌即构成一个时间序列。 时间序列模式的预设setting即马尔科夫链, 之前动力学模式里讲到反馈导致复杂历史路径依赖,当这种依赖的最简单模式是下一刻可能出现的状态只与此刻的状态有关而与历史无关, 这时候我们得到马尔科夫链。
马尔科夫链虽然是贝叶斯时间序列分析的基准模型,然而现实生活中遇到的时间序列问题, 通常不能归于马尔科夫链,却可以间接的与马尔科夫链关联起来,这就是隐马过程,所谓含有隐变量的马尔科夫过程。
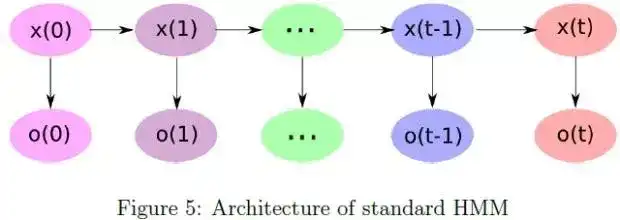

图: 隐马过程示意
语音识别就是一类特别能利用隐马过程的应用, 在这里语音可以看做一组可观测的时间序列, 而背后的文字是与之关联的马尔科夫链, 我们需要从可观测的量, 按照一定的概率分布反推不可观测的量, 并用马尔科夫链的观点对其建模, 从而解决从语音到文字的反推过程。 当今的语音识别则用到下面紧接讲的深度学习模型。
4, 深度学习
刚刚讲的分类问题, 只能根据我们已知的简单特征对事物进行分类, 但假设我们手里的数据连需要提取的特征都不知道, 我们如何能够对事物进行分类呢? 比如你要从照片识别人名, 你都不知道选哪个特征和一个人关联起来。 没关系, 此时我们还有一个办法, 就是让机器自发学习特征, 因此寄出深度学习大法。通常在这类问题里, 特征本身构成一个复杂网络,下级的特征比较好确定, 而最高层的特征, 是由底层特征的组合确定的, 连我们人类自己都不能抽象出它们。
深度学习即数据内涵的模式(特征)本身具备上述的多层级结构时候,我们的机器学习方法。 从以毒攻毒的角度看, 此时我们的机器学习机器也需要具有类似的多级结构,这就是大名鼎鼎的多层卷积神经网络。深度学习最大的优势是具有更高级的对“结构”进行自动挖掘的能力,比如它不需要我们给出所有的特征,而是自发去寻找最合适对数据集进行描述的特征。 一个复杂模式-比如“人脸” 事实上可以看做一个简单模式的层级叠加, 从人脸上的轮廓纹理这种底层模式, 到眼睛鼻子这样的中级模式, 直到一个独特个体这样最高级的复杂模式, 你只有能够识别底层模式,才有可能找到中级模式, 而找到中级模式才方便找到高级模式, 我们是不能从像素里一步到达这种复杂模式的。 而是需要学习这种从简单模式到复杂模式的结构, 多层网络的结构应运而生。
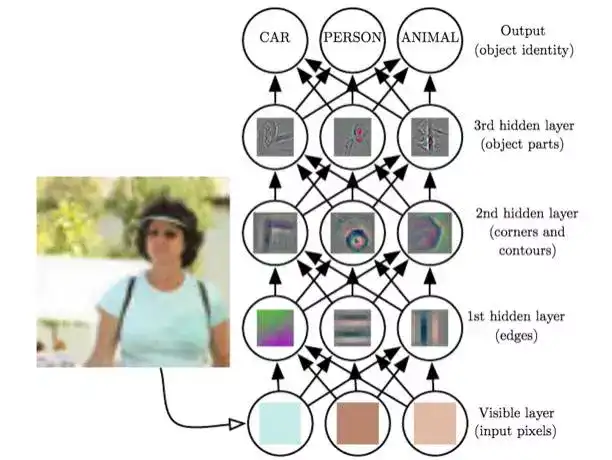
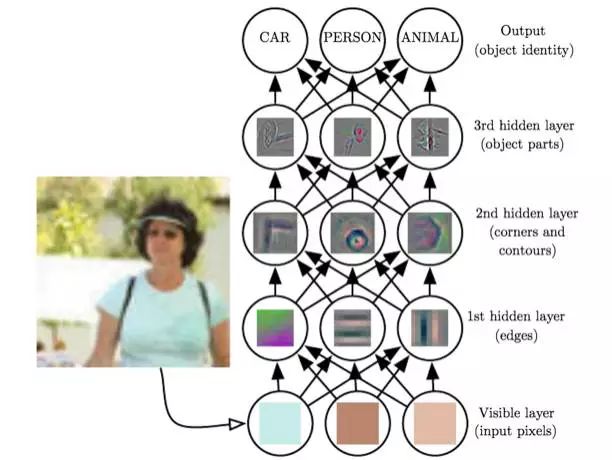
图: 从具体特征到抽象特征逐级深入的多级神经网络
6, RNN和神经图灵机
如果时间序列数据里的模式也包含复杂的多层级结构, 这里和我之前说的复杂系统往往由于反馈导致复杂的时间依赖是一致的, 那么要挖掘这种系统里的模式, 我们通常的工具就是超级前卫的循环神经网络RNN,这种工具对处理高维具有复杂反馈的系统有神效, 因为它本身就是一个高维具有复杂时间反馈的动力学系统。
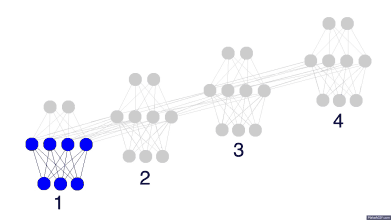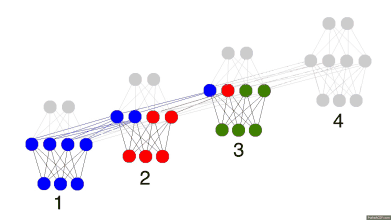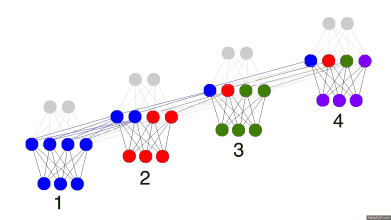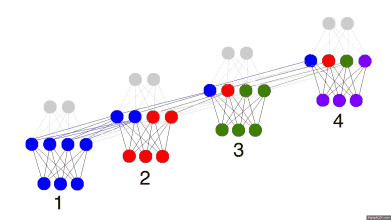
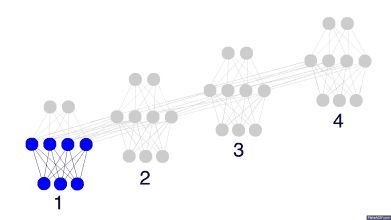
图: 循环神经网络, 过去的信息可以通过循环存储在神经元之间
当一个复杂时间序列的问题里面, 每个时间点的信息都可以对未来以任何方式产生复杂影响, 那么处理这种复杂性的一个办法就是用循环神经网络,让它自发学习这种复杂结构。 比如一个城市里的交通流, 或者人与人之间的对话。
神经图灵机是在多层卷积神经网络或递归网络基础上加上一个较长期的记忆单元, 从而达到处理需要更复杂时间关联的任务, 比如对话机器人。 而神经图灵机最厉害的地方在于他可以通过机器学习传统的梯度下降法反向破译一个程序, 比如你写了一个python程序, 你用很多不同的输入得到很多对应的输出, 你可以把它给神经图灵机训练, 最终本来对程序丝毫无所知的神经图灵机居然可以如同学会了这个程序。
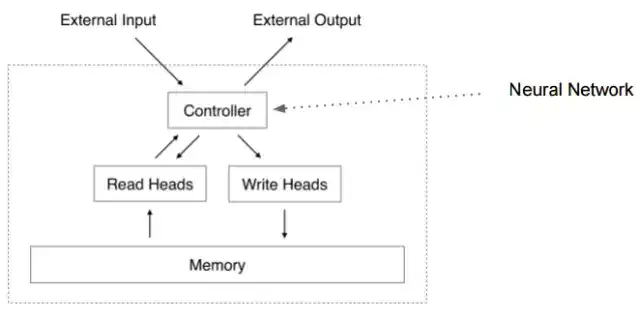
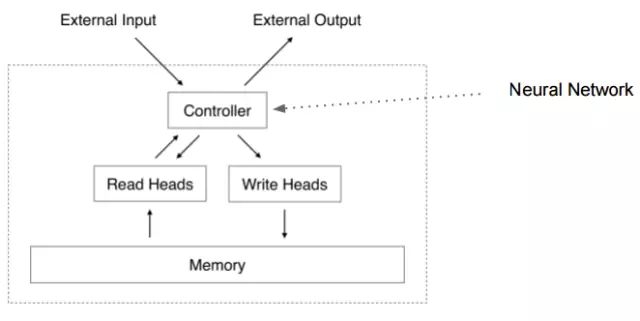
图: 神经图灵机的基本结构, 在多级神经网络或循环网络(controller)的基础上,增加一个更长时间的记忆, 记忆和神经网络之间的读入和写出装置, 整个装置都是可以被人工训练的(可微分)
作者:许铁-巡洋舰科技 著作权归作者所有。来源:知乎
链接:https://www.zhihu.com/question/265034098/answer/326765915