从疾病的暴发,到生态系统的崩溃,临界点是我们所见的最剧烈变化的成因之一。由于其内在本质,这也是最难预测的一类现象。使用机器学习的创新方法,能否破解这一难题呢?PNAS今年9月的一篇论文,令人信服地指出了这种模型具有的潜力。通过在海量模拟数据上训练深度神经网络模型,该文证明了监督学习可以成功地区分在哪些情况下,系统正在走向临界点。

论文题目:
Deep learning for early warning signals of tipping points
论文地址:
https://www.pnas.org/content/118/39/e2106140118#abstract-2
从脑电波到全球气候变化,在一系列复杂系统中都能观测到临界点(tipping point)现象 [2]。这一系列现象背后,有一个被称为临界慢化(critical slowing down,CSD)的共同显著特征[3],这个在突变发生前的临界信号,使得发现通用判别器成为可能。然而,之前数十年的研究说明,这件事说起来容易,做起来难 [4,5]。
基于CDS的方法有一个巨大的弱点,就是找到的规律都过于通用,在灾难性的变化(catastrophic transition)没有发生时也会出现。灾难性的变化最早是由拓扑学家 Rene Thom 提出 [6],他提出了突变理论(catastrophe theory)。临界点不仅发生在数学家称为差异倍数(fold change)的时候,还会在那些并非灾难性的相变点附近出现,例如超临界相变或Hopf 相变[7]。
上述三种造成显著变化的相变现象都曾在自然界中被观察到[5]。例如,由于社会或环境变化,当某种病毒的基本传播系数R0超过1时,超临界相变会发生,这时每个新的病患会传染多于一个患者。三种相变中,只有倍数分叉(fold bifurcation)一旦越过阀值,会造成系统由一个稳定点急剧、不可逆地转移到另一个远处的稳定点,这一现象被称为延迟(hysteresis)。
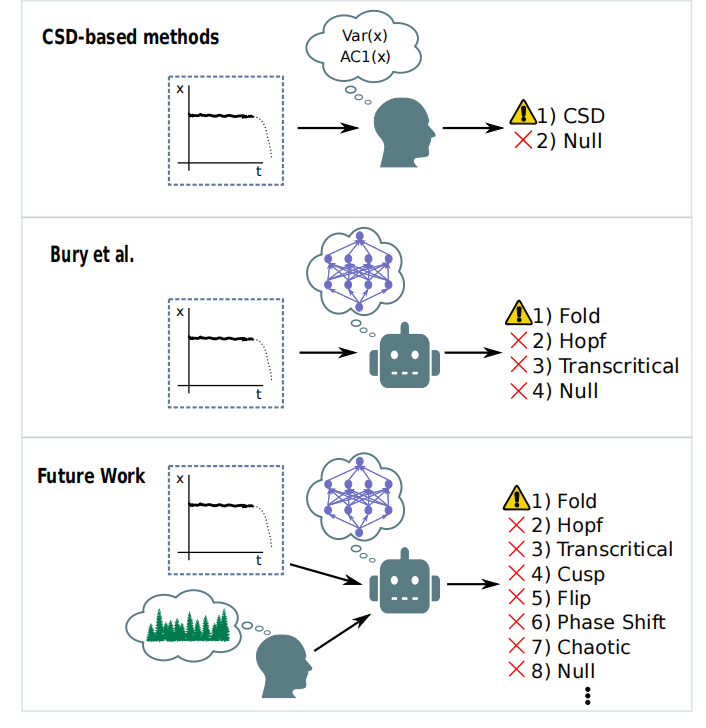 图1
图1
基于临界慢化的临界点预测方法,仅仅依靠统计指标,能够对临界点给出提前预警,但不能区分灾难性和非灾难性的变化。基于深度学习的方法,通过在海量模拟数据的训练,能够准确地区分出灾难性和非灾难性变化。未来的研究可以扩展到更多类型的相变上,并且不仅基于模拟的数据进行训练,还基于真实数据,例如生物体中的时间序列数据。
不同类型的相变使用基于临界慢化的方法,不仅会产生假阳性的预测,即对那些并不是灾难性的相变点给出预警,还经常无法预测灾难性的相变点[9,10]。这些方法需要输入大量高质量的数据,才能对即将到来的相变进行预测。数据的时间不足,或精度不够,都无法进行预测。基于临界慢化的方法之所以缺乏准确度和敏感度,是由于没有看到全局图景。基于深度学习的方法通过对比正常和灾难性变化的方程,找到了全局图景。
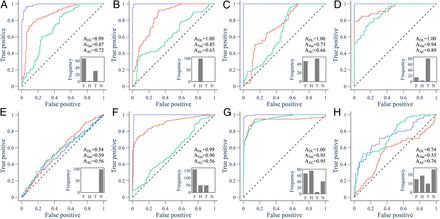 图2. 在不同类的数据上,基于深度学习的模型(蓝线),其代表模型性能的AUC达到了0.8~1,远胜过之前方法。
图2. 在不同类的数据上,基于深度学习的模型(蓝线),其代表模型性能的AUC达到了0.8~1,远胜过之前方法。基于临界慢化的方法类似于管中窥豹,只是从灾难性和非灾难性的图景共有的一阶项中,预测将要发生什么。而每一类相变的规范形式(normal form),则能够显示出不同类相变的微妙区别,且高阶特征能够显示出何时一个灾难性的突变来临。不过,不同于能够通过统计指标简单区分出的临界慢化,这些微妙的高阶特征很难通过简单的统计指标得出。为了克服这一挑战,该研究使用了最强大的分类工具:深度学习。
深度神经网络具备的表征能力捕捉了更多细微的特征,区分出不同类型相变的不同层面。该研究结合了两种著名的神经网络结构:在视觉领域应用广泛的卷积神经网络,以及在自然语言和时间序列数据中应用广泛的LSTM[11],之后在四类数据中训练模型,包括fold、Hopf、超临界相变及中性过程。相比临界慢化方法,训练后的神经网络能够以更高精度识别出这四类相变。
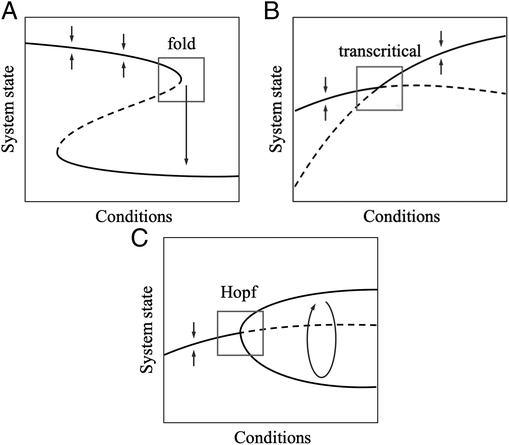
图3. fold、超临界以及Hopf相变的示意图
尽管这样,机器学习模型的性能受限于训练数据,能够准确分区猫和狗的神经网络,却并不能区分鲶鱼。该研究只考虑了三种特定的相变,即在二维的三阶多项式这一条件下。正如作者指出,自然界中存在更丰富的情况,不仅仅是他们设想的局部分叉[12],还包括混沌动力学[13]、相变[14]及随机过程、非平稳或长时间的瞬态动力学[15],以及其它只可能在高阶模型中出现的现象。将这些纳入模型中将显著增加分类难度,可能需要未来在设计和训练神经网络上的技术创新。
尽管如此,需要注意的是,这些神经网络被训练的是数学而非生物学。尽管深度学习模型能够识别出高阶项中的潜在特征,但其不具有人类研究者所掌握并引入研究的背景知识。例如,在这一系统中,另一个稳定点是否已经被识别出?诸如合作性的社交行为这样的正反馈,能否促成 fold 相变发生的条件?相变是在什么时间尺度上发生的,又是在什么样的变化的环境中发生的?
如果说,不考虑系统的特异性是临界慢化方法的优势,那么这也是其最大的弱势[16]。相比统计方法,机器学习方法能够在没有先验假定,不清楚具体细节的情况下,尽可能地利用系统的生物学背景。未来的研究应该尽可能在模型训练中引入生物学细节,这样模型不仅能学到数学,也能学到生物学。
通过不仅仅展示模型的结果,还公开训练用到的源代码和数据,该研究为未来研究奠定了基础。对于任何一个研究团队来说,训练一个通用的灾难性突变的预警模型都是一大挑战。但这也不必一蹴而就。各领域的研究者,可以通过提供超越多项式模型的临界突变的模型和数据,为此添砖加瓦,最好这些数据不仅仅是数学描述,还有生物学注释。随着训练数据的多样化,有监督的模型会变得越来越难以训练,但可以成为计算机科学界的公开挑战,用以衡量其算法在这些重大科学问题上的表现。